
Sabemos que buscar ofertas laborales en cada uno de los portales más populares puede tornarse repetitivo, mecánico y tedioso, ya que todos tienen diferentes mañas a la hora de buscar y filtrar.
Por eso, uno de nuestros objetivos nucleares en MiGuru es simplificar el proceso de búsqueda, para que puedas hacerlo desde un solo lugar y con la misma interfaz. A continuación, te contamos cómo consolidamos distintos portales en una sola plataforma, desde la integración, hasta que encuentras una oferta perfecta para ti y envías tu postulación.
Elegir un portal nuevo 👀
El primer paso del proceso consiste en observar el tipo y cantidad de ofertas que dispone el portal bajo análisis. En general, solemos priorizar la implementación de sitios con mayor flujo de ofertas, como Computrabajo o Laborum, que suelen agregar cientos o miles de vacantes diarias. Sin embargo, hay job boards de nicho, como lo son Get On Board para tecnología, o Pegas Con Sentido para empresas de índole social, que también nos interesan por la calidad y relevancia de sus ofertas.
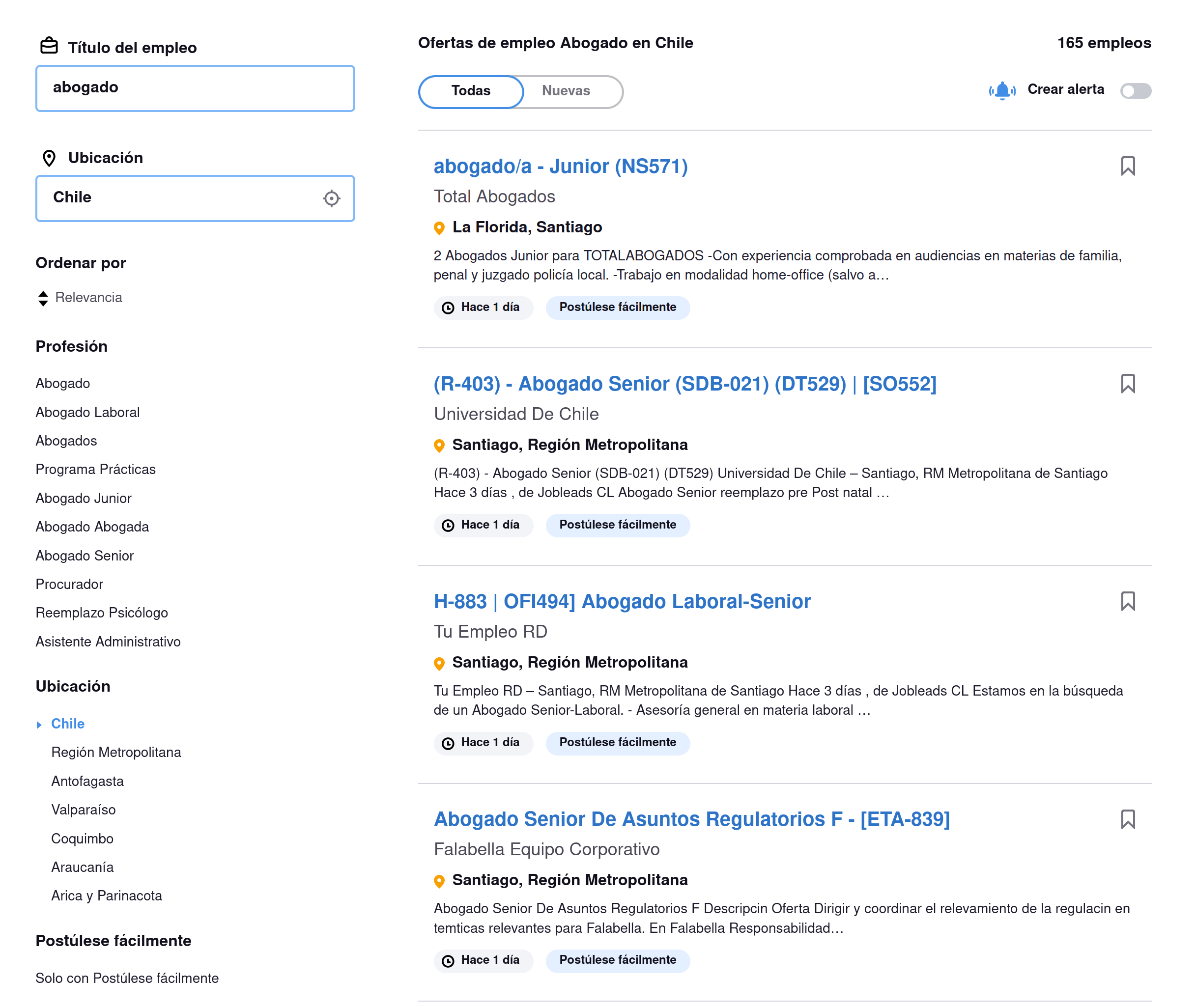
En el ejemplo de la foto, si buscamos por el título "abogado", obtenemos la friolera de 165 resultados, varios de ellos de hace un día. Da la impresión que es un portal de bastante flujo... Sin embargo, cuando entramos a ver el detalle algunas ofertas, nos damos cuenta que en realidad este sitio solo actúa como intermediario de otros. En la siguiente foto, vemos que la primera oferta en verdad viene de Kit Empleo, un portal para el cual ya hicimos este análisis y pasamos a la fase de implementación.
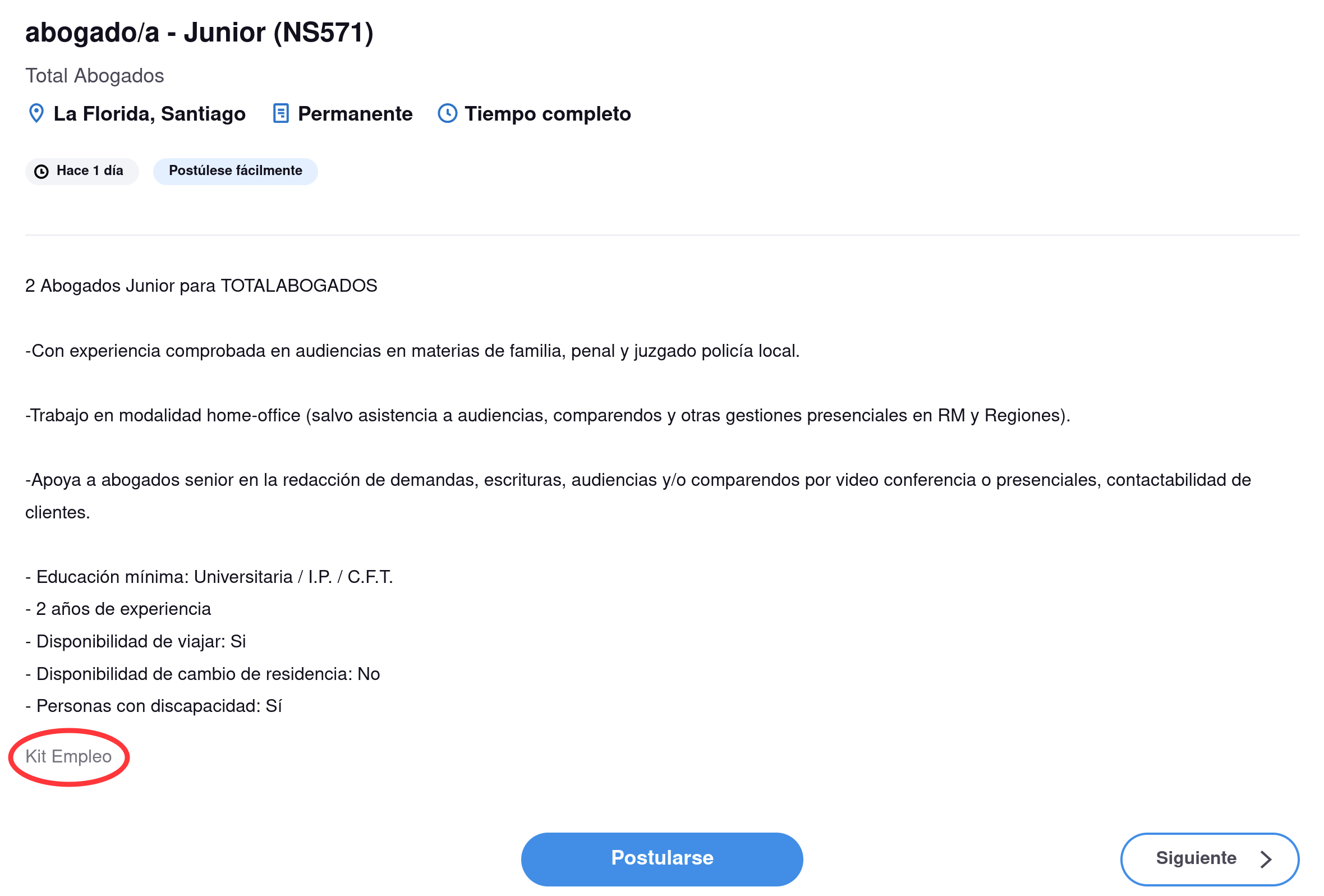
Como no queremos tener muchas ofertas duplicadas (lo que solo se traduce en ruido para nuestros usuarios), en este caso preferimos no pasar a la siguiente fase.
Implementar un crawler y un scraper 🤖
Si encontramos un portal con suficiente tráfico, que aporte ofertas nuevas (i.e. que no haga "eco" de otros sitios), o bien que tenga vacantes de nicho y alta calidad, entonces pasamos a la etapa de implementación.
Acá es donde usamos dos términos de la jerga computina: crawler y scraper. El primero viene del inglés to crawl, que se traduce como gatear. De la misma forma que una guagua llega a los lugares más sorprendentes gateando, la idea es que este pedazo de software escanee meticulosamente el sitio desde el cual queremos obtener ofertas y postular, para luego presentarlas al segundo proceso, el scraper.

El origen del término scraper quizás no hace tanto sentido (si sabes, porfa cuéntanos!), pero en inglés, to scrape significa raspar. Probablemente se asocie con raspar o quitar lo innecesario de una página web para dejar lo esencial (y luego almacenarlo).
Does anyone know the etymology/first usage of "web scraping"? Seems likely it's a variation on "screen scraping" but I'm curious how we ended up with that verb, esp since other alternatives like "crawling" seemed ascendant in the 90s
— Noah Veltman (@veltman) November 11, 2021
La mayoría de las plataformas de empleo se estructuran con dos funciones claramente diferenciadas: un buscador (como Google), que entrega títulos de oferta y un poco más de información, como el nombre de la empresa o la ubicación del puesto de trabajo y, por separado, una vista con el detalle de la oferta, con los requisitos del cargo y el sueldo. Por lo anterior, la mayoría de nuestros crawlers simulan a un usuario haciendo búsquedas y recopilan solamente los links a las ofertas que aparezcan como resultados. Por otra parte, los scrapers son un poco más elaborados, ya que visitan las URLs encontradas por los crawlers, leen la información del detalle en el formato específico de la página y la transforman en un esquema común para todas las ofertas en MiGuru.
Como somos fans de Python, tanto crawlers como scrapers los construimos con las librerías requests o httpx para hacer las solicitudes HTTP, y BeautifulSoup para parsear el contenido HTML de los sitios. Algunos usan APIs en formato JSON, lo que nos ahorra bastante juego con selectores que, por lo demás, se pueden romper fácilmente si deciden darle un nuevo look al portal.
Hasta el minuto, no nos hemos visto obligados a usar Selenium o Scrapy, pero no descartamos usar esas librerías más potentes para portales con mucho procesamiento desde el lado del cliente. Lo bueno de las librerías que usamos es que son bastante rápidas, ya que simplemente parsean texto y no requieren renderizar estilos o interpretar JavaScript.
Revisar periódicamente el portal ⏰
Ya estamos casi terminando! Solo falta que agendemos una visita del crawler al portal cada unas cuantas horas para no perder ninguna oferta interesante, y de alguna forma avisarle al scraper que tiene trabajo por hacer cuando el crawler ha encontrado vacantes nuevas.
Para este propósito, nos mantenemos fieles al ecosistema Python y usamos el orquestador de trabajos distribuidos Celery. Esta librería tiene la gracia que puede enviar trabajos de crawling o scraping a máquinas físicamente distintas, permitiendo distribuir la carga entre ellas. Por el momento, con una sola instancia t3.small en AWS hemos aguantado bien, pero apenas necesitemos monitorear ofertas en muchos más portales (como de otros países por ejemplo 😏), escalar horizontalmente va a ser esperemos trivial.
Celery nos permite agendar tareas recurrentes à la crontab, además soporta lógicas para reintentar una tarea fallada, esperar cada vez más entre reintentos (como exponential backoff) y se puede conectar una interfaz web bastante útil para monitorear el progreso, las tareas completadas y sus resultados.
Prestar atención a las fallas 🔥
Lamentablemente, los scrapers son extremadamente propensos a romperse, ya que para funcionar, normalmente se basan en el layout del sitio e instruyen a la librería BeautifulSoup a que retorne, por ejemplo, todo el texto que esté dentro de un <div> con una clase específica, y que venga seguido por otro <span>. Basta que los desarrolladores del portal cambien un poco el look y nuestro scraper estrella probablemente fallará.
Por lo anterior, en MiGuru tenemos mecanismos de alerta para cuando un portal tiene una tasa de fallas excesivamente alta. En algún momento consideramos enviar una alerta por Slack, pero la verdad es que es súper común que los portales fallen con errores de servidor (estado 500) o que se interrumpan las conexiones, entonces quizás sería una fuente de alto spam.
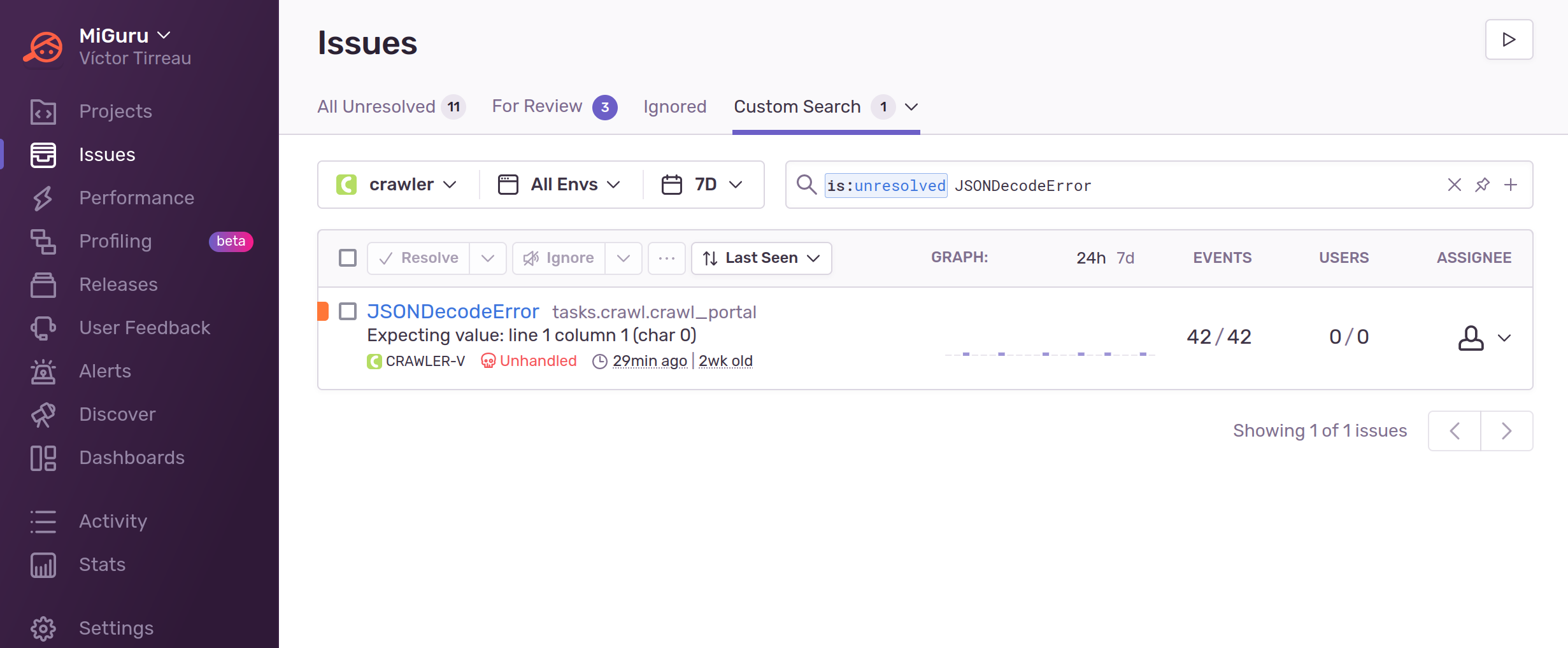
Hoy usamos Sentry para alertarnos de alguna falla recurrente en el proceso de encontrar o descargar ofertas. Tiene la gracia de que agrupa los errores que considera son reincidencias, así no nos muestra 42 veces el mismo JSONDecodeError. Además, cuando cree que no es un one-off error, entonces gatilla un mensaje que nos llega a Slack y así podemos incluirlo en la priorización para arreglarlo.

